Дисперсия окажется большей при множественной регрессии, и разница будет тем больше, чем коэффициент парной корреляции ![]() будет ближе по модулю к единице.
будет ближе по модулю к единице.
Теперь, пусть переменная y зависит от двух факторов x1 и x2:
![]() однако мы не уверены в значимости фактора x2, и поэтому мы запишем уравнение регрессии так:
однако мы не уверены в значимости фактора x2, и поэтому мы запишем уравнение регрессии так: ![]() или
или ![]()
Если выбросить x2 из регрессионной модели, то x1 будет играть двойную роль – отражать свое прямое влияние на объясняемую переменную y и заменять фактор x2 в описании его влияния. Это опосредованное влияние величины x1 на y будет зависеть от двух обстоятельств: от видимой способности переменной x1 имитировать поведение x2 и от прямого влияния x2 на y. Способность переменной x1 объяснять поведение переменной x2 определяется коэффициентом наклона h линии псевдорегрессии: ![]()
Величина коэффициента h рассчитывается при помощи обычной формулы для парной регрессии
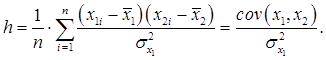
Влияние х2 на у определяется в адекватном уравнении регрессии коэффициентом b2, и таким образом, эффект имитации посредством величины b2 может быть записан как ![]() (прямое влияния величины х1 на у описывается с помощью b1).
(прямое влияния величины х1 на у описывается с помощью b1).
При оценивании регрессионной зависимости у от х1 (без включения в нее переменной х2) коэффициент при х1 определяется формулой ![]()
При условии, что величина х1 не является стохастической, ожидаемым значением коэффициента при х1 будет сумма первых двух членов последней формулы. Присутствие 2-го слагаемого предполагает, что математическое ожидание коэффициента при х1 будет отличаться от истинной величины b1, то есть, другими словами, оценка будет смещенной. Величина смещения определится выражением
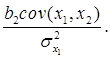
Направление смещения определяется знаками b2 и cov(x1,x2); иногда смещение бывает настолько сильным, чтобы заставить коэффициент регрессии сменить знак.
Если ![]() то смещение исчезает.
то смещение исчезает.
Другим серьезным следствием не включения переменной, которая на самом деле должна присутствовать в регрессии, является то, что формулы для стандартных ошибок коэффициентов и тестовые статистики, вообще говоря, становятся неприменимыми.