Выявление гетероскедастичности
Это достаточно непростая задача; дисперсию σ2(εi) обычно определить не удаётся, так как для конкретного значения объясняющей переменой хi или конкретного значения вектора x при множественной регрессии мы располагаем лишь единственным значением зависимой переменой уi и можем вычислить единственное модельное значение переменной ![]()
Тем не менее, в настоящее время разработан ряд методов и тестов для обнаружения гетероскедастичности:
1. Графический. Мы уже говорили, что М(εi)=0; это значит, что дисперсию остатка можно заменить её оценкой, а в качестве этой оценки можно взять величину ![]() . В таком случае можно построить график в координатах
. В таком случае можно построить график в координатах ![]() есть функция от хi, и по нему изучить характер указанной зависимости. Если объясняющих переменных несколько, то проверяется зависимость по каждой переменной хj , то есть изучается зависимость
есть функция от хi, и по нему изучить характер указанной зависимости. Если объясняющих переменных несколько, то проверяется зависимость по каждой переменной хj , то есть изучается зависимость
![]()
Можно также исследовать зависимость ![]() , так как переменная у является линейной комбинацией всех объясняющих переменных.
, так как переменная у является линейной комбинацией всех объясняющих переменных.
2. Тест ранговой корреляции Спирмена. Значения xi и εi упорядочиваются по возрастанию, и для каждого наблюдения в ряду х и в ряду ε устанавливается свой ранг (номер) в соответствии с этим упорядочением. Разность di между рангами x и ε для каждого номера наблюдения рассчитывается как ![]()
Затем вычисляется коэффициент ранговой корреляции
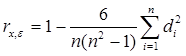 .
.
Известно, что если остатки не коррелируют с объясняющими переменными, то статистика
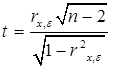 имеет распределение Стьюдента с числом степеней свободы
имеет распределение Стьюдента с числом степеней свободы
df = n−2.
Если вычисленное значение t-статистики превышает табличное критическое значение при назначенном уровне значимости γ гипотезы Н0, то гипотеза ![]() об отсутствии гетероскедастичности отвергается и гетероскедастичность признаётся существенной. Критическое значение t-статистики определяется по таблице как
об отсутствии гетероскедастичности отвергается и гетероскедастичность признаётся существенной. Критическое значение t-статистики определяется по таблице как
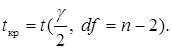
В том случае, если модель регрессии множественная, проверка гипотезы Н0 выполняется для каждой объясняющей переменной.
3. Тест Гольдфельда–Квандта. Предполагается, что дисперсия остатков в каждом наблюдении пропорциональна или обратно пропорциональна интересующему нас регрессору, также предполагается, что остатки распределены нормально и нет автокорреляции в остатках.
В случае множественной регрессии тест целесообразно проводить по каждому регрессору отдельно.
Последовательность проведения теста:
а) наблюдения (строки таблицы) упорядочиваются по возрастанию интересующего нас регрессора;
б) упорядоченная таким образом выборка разбивается на 3 подвыборки объемами ![]() ,
, ![]() ,
, ![]() , при этом
, при этом ![]() Можно считать, что
Можно считать, что ![]() Авторы теста предлагают следующие значения: n = 30, k = 11; n = 60, k = 22; n = 100, k = 36…38; n = 300, k = 110 и так далее (см. табл. 8.1);
Авторы теста предлагают следующие значения: n = 30, k = 11; n = 60, k = 22; n = 100, k = 36…38; n = 300, k = 110 и так далее (см. табл. 8.1);
Таблица 8.1
|
I |
k |
k > p+1 k ≈ n/3 |
|
II |
n–2k | |
|
III |
k |